Vibecoding the mood.site Premium Update
On using Cline and Claude Code to release a major update to production software
April 18, 2025
I’ve just released a big update to my image gallery moodboard website app thing mood.site. I talk more about the specifics of the update on the new release notes page for it, but the TLDR is that I:
- Re-architected the site with Svelte
- Added in lot of customization options
- Made the site much faster
- Added in the ability to pay for it
Those bullets are each doing a lot of work (it is a TLDR), so I really recommend you just going to the site and looking at settings to see what’s possible now.
Here’s the diff of the work:
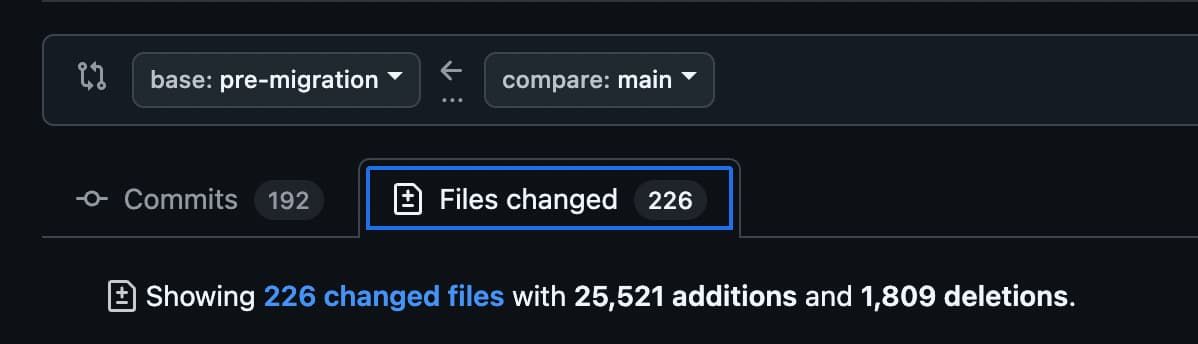
It was a lot. But here’s the kicker — I personally wrote probably only about ~50 lines total of that.
Ye Olde AI Tools
I made mood in the first place as an exercise to find out “how good is AI coding actually”. I came away thinking
- It was a lot better than I would have thought, especially if I had I not done it in the first place
- It needed a lot of babysitting to make sure things didn’t go awry.
- The workflow was pretty awful. This was pre Claude “Workspaces” and Projects and larger context models, and instead in limited-context March 2024 ChatGPT copy and pasting code back and forth. Copilot itself wasn’t even in VS Code and was added in about a month after I released mood.
The whole process felt like an experiment. The tools weren’t well suited to the task, and the iteration loop was slow. I could also see it actively falling over at certain points as it would lose context of the conversation and start to reinvent things it had already done. I knew I could do some things faster than the AI was doing it, but stubbornly adhered to the mission and, in my opinion, ended up pushing at the boundaries of what “working with AI” was at that point in time. It was a fruitful experiment, but I felt like more needed to happen before I tried something like that again.
Luckily a year later, armed with a small pile of general todos and user feedback from a year of mood, more has indeed happened. So much so that it made me think it was time to dust off the mood code and embark on the experiment once again.
I started to envision “The Premium Update” — a stepwise increase in mood’s functionality as well as the ability to actually pay for the site for some nice benefits. I started to collect a handful of features and ideas, and set about trying to figure out how I’d make it all happen.
A Context Aside
Step one of this was making mood itself more copacetic to working with AI. Given its provenance as a continual chat interaction with ChatGPT, it started out as basically just four giant JS files. This isn’t great for either me or the AI, so the first thing I wanted to do was add some actual structure with a framework and break up the mega files into smaller, more composable fragments — this would help me to understand and reason about the codebase (when necessary), as well as reduces context pollution for the AI. Instead of giant files going into context, a smaller subset of smaller files would enter, giving the AI a more “trim” set of code to work with that is (ideally) only exactly what you need.
Managing context was a big deal implicitly for the ChatGPT version of mood because context itself was so limited. It was very easy to effectively run out of “memory” and need to re-tell it what you told it 40 messages ago. Newer models with larger context windows have a sort of reverse problem: because what’s in context and how it is retrieved is non-specific/generic, each addition to context dilutes the value of what is already in context.
It’s really easy to think that, with large context models, you can just dump your codebase into a model and it will magically fix all your code and solve all your bugs. This is not the case. I would go so far as to say that instead, managing context is the most important part of AI coding right now. Specifically because there is a real bell-curve of performance that looks like this:
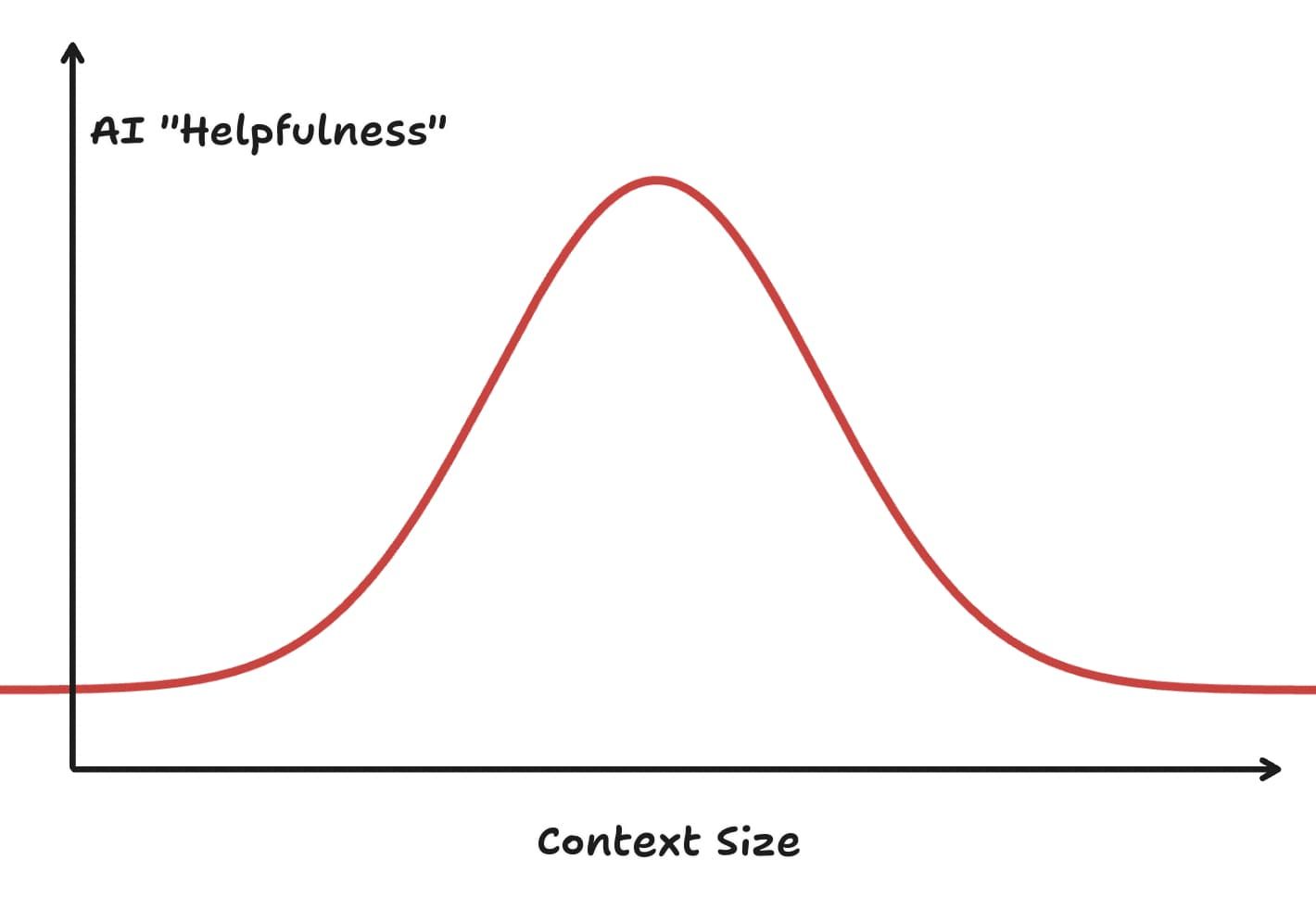
As you add more and more context, an AIs ability to reason about the task at hand can start to diminish. I want to be careful to not overstate this, as it’s very possible this will change. But I feel like, right now in April of 2025, learning how to effectively manage context for a model is the most important part of AI-assisted coding. I have seen very few tools that directly consider and think about context directly, but I suspect we will see some very soon that further emphasize this aspect.
Step 1 - Break the Files Up
Mood’s handful of thousand line JS files naively blasted into context were, as such, not incredibly helpful. In the “insert file to context” model, I needed smaller files that could be more contextually brought into context, keeping things trim and on task without polluting a given query with unrelated code.
So, step one: break the files up. Make the codebase itself more copacetic to AI development by providing smaller “units” of files that can be inserted into context. I chose Svelte for this, as I’ve used Svelte before in non-AI times, and I find that (good) Svelte code can be pretty modular and composable.
Refactoring a codebase into a new framework is usually a “rebuild it from scratch” type of task. It’s also the type of task that the old model of purely chat input would do poorly at due in large part to context pollution. It would require you pasting in all your codebase’s files at the start (lots of context), and the outputs over time (also in context) would start to overload the AI with what it needed to know.
However, having continued working with AI tools over the last year, I knew that “translate this code-ish thing into this other code-ish thing” was a task AIs were incredibly well-suited for. I don’t think people have properly internalized this — most all frontier/SOTA AI models are really great transpilers for converting code from one language to another. It’s obviously not actually doing syntax tree walking type work, but is just as effective and effectively effortless.
Translating a framework-less JS project to a framework like Svelte then was something I knew the AI could do well — the question though was “where?”
Since using ChatGPT for the first version of mood, I had since migrated over to Claude Sonnet, in part due to them first implementing the Artifacts concept, allowing “the work” to (at least visually) sit separate from the chat context discussing it. Context length increased, and I also started working with their Projects tool a bit.
These improvements were great, but still both suffered the same fatal flaw — the “work” wasn’t actually happening where “the work” was happening. Managing Artifacts and Projects still required lots of tending to make sure the AI has access to the latest code. If you made local changes to a file from an Artifact or Project, it was on you to re-upload that file in the relevant place. When you’ve got lots of files, this is incredibly tedious.
If I was going to try to do this migration with Claude’s interface, I would need to constantly be uploading new file versions to projects over and over again. I didn’t want to do this.
Cline Opens My Third Eye
Around the time I started to feel these limitations, I had also started hearing about Cline. Cline is a VS Code extension that pitches itself as a “fully collaborative AI coding partner”. Some people may also call it “agentic”. What this means in practice is that, inside VS Code (aka where “the work” actually happens) it can:
- Proactively gather files for context on a given problem
- Read files
- Write files
- Edit files
This sounds great! No more copy/pasting, no more managing a secondary repository of all the relevant code for a given project. It works next to your code, instead of somewhere else.
Cline also had the ability to use Claude 3.5 itself, so it seemed like I could get the best of both worlds. Claude for the actual LLM work, and its output being inside the editor I was actually working in.
Getting started with was easy — I just download the extension, and tried putting a task in the prompt:
I would like to migrate the client code here to use Svelte 5 (instead of how it is now, which is framework-less). As a reminder, here’s the page on migrating to Svelte 5 https://svelte.dev/docs/svelte/v5-migration-guide (NOTE: Cline didn’t have web access at this point, so this was an error on my part!)
And… woah (video from Cline’s website)
I think it’s hard to overstate the third eye opening that happens the first time you use a tool like this. It is such that it is hard for me now to imagine the world before tools like this, as it, almost immediately, completely changed how I think about writing software and demonstrated stepwise growth in AI coding tools.
Every file read and write I saw Cline doing was time I knew I was saving by not needing to manually copy and paste the relevant files to a Chat AI in order to give it the context it needed. Cline now automatically did this to largely great effectiveness.
Chat AI centric AI coding felt like having to guide baby AI to find the right answer that you already knew. Cline instead felt like that baby grew up into a boy scout, eager to take your instruction and guidance and move boldly towards a solution.
Cline does have its own guardrails, with the ability to manually approve every file read/write, but after working with it for a while and reviewing its changes, I became confident enough to just auto approve every read/write and let it work without me interfering.
This type of coding got a name a few months ago from Andrej Karpathy himself — “vibecoding”:
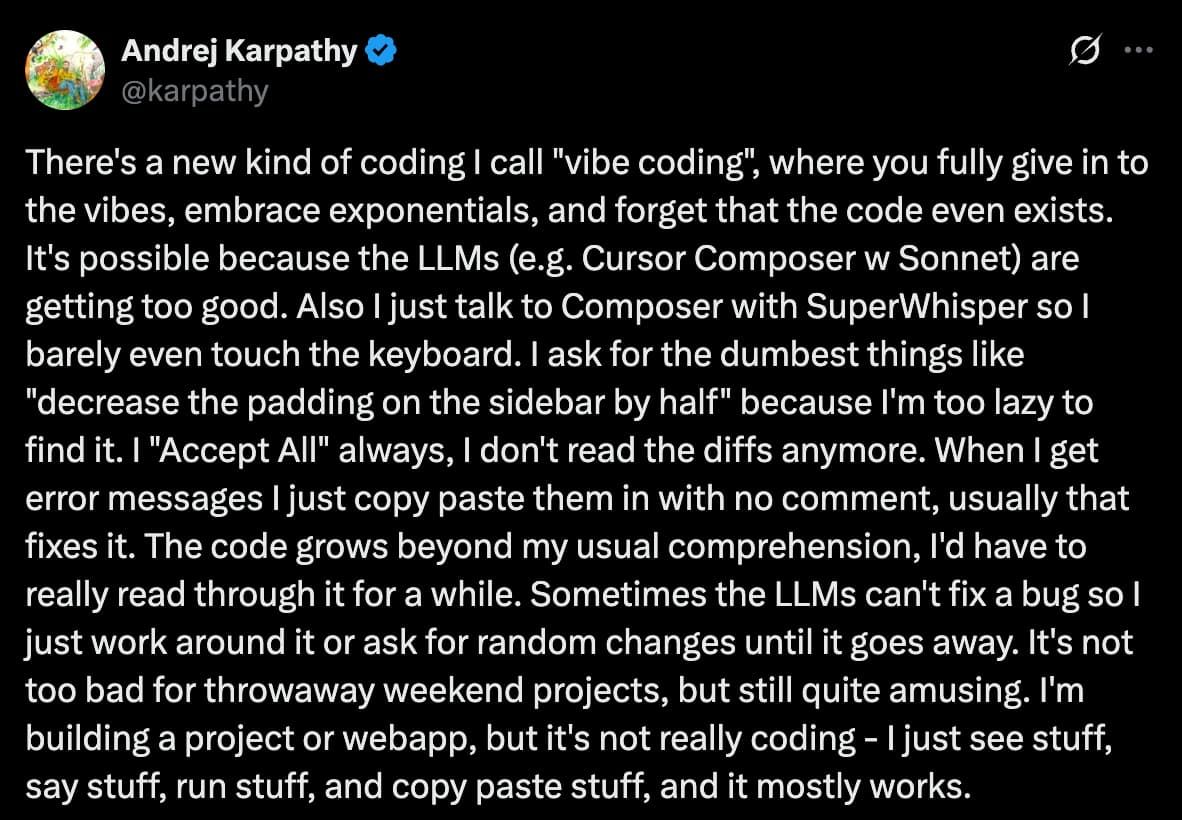
Working with Cline like this, I was starting to feel the vibe.
Working With Cline
I would enter tasks that I wanted Cline to do, and it would dutifully try and do them, reading and writing whatever files it needed to along the way. The workflow I started to mostly fall into was:
- Give Cline a task
- Auto approve all change/reads
- Once it was done with its task, check that the task is actually functionality completed on the app
- If not, re-prompt with the edits that needed to be made
- Repeat step 2-4 again until it all works
- Check the diffs in Code or GitKraken and then commit
In general, this works great, especially if you’re working on tasks the AI would be predictably “good at”. Where it starts to fall apart is in how many times you need to do steps 2-4. I found that, paradoxically, the more I needed to iterate on the specifics of a task, the harder time the AI had with completing it.
This is largely (IMO) due to context pollution. As edits and changes are made to files, not only do the files and their versions shift around and get re-added in the AI’s context, but programming is still programming. Something as simple as having a minus instead of a plus somewhere can wreck your whole app, and the AI (for now) especially struggles with finding functional runtime errors like this.
And because we’re starting to vibe here, we are also exceptionally bad at finding these errors. After a few rounds of Cline in your codebase on substantial features, it’s easy to lose context on what the code is supposed to be doing, so you searching for a bug like this can similarly be a needle-in-haystack situation.
For example, I had a bug with mood near the end of the Premium update development work where network requests would race each other to return. The requests would then saturate values that were inside of Svelte {#if} statements: {#if !isLoading1 || !isLoading2}. These were followed by an {#else} declaration that would render the actual gallery container — the logic being if we aren’t loading, we show the gallery. However, I was encountering an issues on some large boards where images would load in without a properly initialized gallery container and would hence display improperly. What was going on?
Claude Code (which I had switched to later on, more below) and Cline both absolutely fell over on this. They had no idea what was going on and were proposing completely unrelated fixes due to misdiagnosed symptoms of other parts of the code. Trying to continue to solve this issue was producing more bad context, with more bad solutions, and those additions themselves were breaking other things.
The issue ended up being how Svelte specifically processes templates, such that a change in isLoading2 or isLoading1 would re-render the template such that it would wholesale wipe the instantiated gallery from the {#else} statement. This is a nuanced bug that requires intermediate to advanced knowledge of Svelte as well as what my code specifically was doing.
Fixing this echoes something something Simon Wilson called out in his great article on using LLMs to code:
Be ready for the human to take over
I don’t necessarily get the sense that anyone besides programmers or programmer-adjacent people are “vibecoding,” but it’s worth saying that to leverage all of this effectively, you still need to be a programmer. For now. These “human in the loop” shaped bugs like the above would absolutely stop a project in its tracks if the person that got this far wasn’t a programmer. Only because I’ve been programming for a long time at this point, and have read and understand how Svelte works, and understand how the code the LLM wrote works, understand how to use the debugger in Chrome, etc. was I able to fix this.
I also want to call out a pretty great resource in addition to Simon’s post: AI Blindspots by ezyang. It’s a great field notes overview of things LLMs can struggle with and what to be aware of.
Working With Cline After Working With Cline
Fixing code like in the above example that is “correct” in terms of syntax/compilation, but is functionally wrong, is difficult for the AI to fix. The way to get an AI to fix this is to describe what is wrong very specifically, but obviously if it’s broken and you don’t know what’s wrong or how to describe it, it will fail. Describing the problem in detail would likely result in you basically saying exactly what’s wrong — which we don’t want, we want the AI to figure it out!
You can also maybe see the paradox here:
- As bugs get more specific, the amount of relevant context to required to fix them needs to go up
- The more we add to context the harder it can be to figure out what/where the bug is.
This specific nuance of AI coding is THE thing right now (IMO). Finding the best ways to feed relevant, specific context to an AI to solve a problem is paramount to solving the issue at all.
Where AI excels though is doing larger, blue ocean type work where it’s going from 0 to 1 instead of 1 to 1.02.
After having worked with Cline a fair bit, I started to change my workflow. Keeping the above paradox in mind, I started to instead lean more on one-shot-ish attempts to implement or fix something, and do light, follow-up corrective prompting to better hone a solution. If it didn’t get within striking distance on its first pass, I’d throw out the solve and start over. Otherwise, I know I’d just be wasting time trying to correct it rather than reprompting it wholesale.
It’s the type of thing you start to develop an intuition for, when you can tell the AI is getting a bit lost in the proverbial sauce and you have to just cut it off and start over. Seeing those dollar amounts in Cline stings a little bit to know it wasn’t directly value added to the codebase, but with each iteration I’m also learning something. $1-2 here or there to better understand the intricacies and potential pitfalls for a given task does still feel worth it.
Cline Acting vs. Planning
One interesting development along the way of using Cline for the Svelte migration was the release of a feature that allowed you to toggle between an “Act” and “Plan” mode.
Previously, Cline was always action oriented, and wouldn’t necessarily “introspect” its own solution before acting, but would instead gather up lots of files based on some idea of what was wrong and then start immediately working on them.
The addition of “Plan” mode allowed Cline to instead muse on its own understanding/plan of action to solve a given task before actually editing anything, and would allow you to provide feedback on its plan and alter it before acting.
(Notably, this is/was not a toggle between reasoning/non-reasoning models, but instead changes the underlying prompt for Cline at will so you can get it to “think” about a problem before actually doing any of the code work, and then “inject” that thought into the work via Act mode.)
I started to use this feature extensively. What I liked most about it was that it made the whole process feel a bit more like a normal software development process. Before writing code, you discuss and plan routes of implementation before actually doing them.
The over-eager Act-only Cline would edit files without really telling you why. It would (and still does) summarize its own action after it deems something complete, but at the start of action it could be vague as to what idea it was operating off of. Notably, Cline did generally make “good” decisions so it wasn’t as if it was ineffective before Plan mode, but sometimes you wanted to capture some nuance or edge to an implementation that wouldn’t necessarily be possible from just an initial prompt.
Especially with bug fixing, Plan mode was a major boon. Getting Cline to outwardly “think” about a bug in Plan mode before then tackling it in Act mode seemed like a double digit increase in accuracy. Any time I found a bug I would describe it in Plan mode and get Cline to then also think about it, and then toggle on Act mode when it seemed like it had a good enough understanding to get started. An Act-only Cline uses its first best guess and would just get started, reducing its ability to suss out nuance for anything subtle.
Plan mode additionally made it a lot easier to do things like requirements definitions at the start of a task, suss out edge cases, etc. Given that you can swap readily between Act/Plan mode at will, it’s almost as if you are basically having Cline write your “Act” prompt first with a conversational LLM, as your conversation history, etc. shares context with Act mode. Additionally, it also helps you let the AI share it’s actual domain/technical knowledge with you and what it thinks is best!
This also touches a bit on the Simon Wilson post again:
LLMs amplify existing experience
I had a rough sketch for how I knew things should work, guided in part by the fact there was already an existing codebase and functioning app, and another project I had used Svelte extensively on. I read up again on the latest Svelte 5 docs to update my own understanding of Svelte before embarking on this, which better helped my ability to both provide guidance for how the LLM should write code as well as pitfalls I could easily identify.
The Plan mode really felt like it was able to take these sketches and flesh them out before then tackling them, allowing me to save time on doing a ton of definition myself and instead feel like I was pair programming with someone that had great ideas and would take notes for me.
Cline Conclusions
My experience with Cline was pretty incredible. It made me believe even more in AI-centric coding. However, over the course of using it, I started to notice a few things:
- Cline is very talkative, maybe even distractingly so. I don’t really need the personification
- If I’m checking diffs, I just look in GitKraken
- Context pollution remains a problem — it’s very easy, for a “difficult” question, for Cline to quickly bring all your workspace files into context
This is all tractable, but you’ll notice something here — I’m not really using VS Code. The AI tools themselves got so good they started to sort of obviate the need for the editor itself.
I’ll hand edit some CSS or other specific code functionality when I need to fix a bug, but I’m largely not using the editor. It is fun to watch Cline move around and edit all your files, but that’s all kind of ancillary to the actual output.
Additionally, working with Cline always felt like it required some ceremony. I could easily be projecting here, but seeing how chatty it was, the need to be inside VS Code, the small Chat UI, the plan/act toggle — it started to feel like a bit much, especially when the results themselves were good.
Anthropic Releases Claude 3.7 and Claude Code
Luckily, by the time I was near the end of the Svelte migration with Cline and had feature parity with the old site, Anthropic released two new things: Claude 3.7 and Claude Code.

As mentioned above Claude was (and is) my go to model. Sonnet 3.5 did all the Svelte migration in Cline, so upgrading to 3.7 was a no brainer.
However, Claude Code offered more interesting. From Anthropic:
Claude Code is an agentic coding tool that lives in your terminal, understands your codebase, and helps you code faster through natural language commands. By integrating directly with your development environment, Claude Code streamlines your workflow without requiring additional servers or complex setup.
It’s basically “Cline in a terminal,” with direct access (and no token limit) to the Anthropic API.
I thought I’d give it a try.
I haven’t looked back.
Claude Code
 Claude Code reimagines the “agentic” experience of Cline as something more universal — it’s literally just a tool that runs in your terminal, and as such can be used for effectively any text-based files. It’s obviously very good at code, but can be also used for docs, csvs, etc.
Claude Code reimagines the “agentic” experience of Cline as something more universal — it’s literally just a tool that runs in your terminal, and as such can be used for effectively any text-based files. It’s obviously very good at code, but can be also used for docs, csvs, etc.
It’s also fast. Cline likes to display a neat trace of its own activities in a way that is nice for a human to look at but kind of wastes actual iteration time. Claude Code acts more like a cron job that spits out its results at the end (in a nice-to-read fashion) but is more “silent” during operation.
Additionally, Claude Code had another trick up its sleeve.
Remember how I mentioned above about context-management as a crucial part of AI coding work? Well, unlike Cline that (at the time) would just dumping relevant files into context, Claude Code instead leveraged its existence as a command line tool to instead use tools like grep in order to efficiently find what it thinks are relevant parts of text corpus to operate on.
Instead of dumping whole files into context, by leveraging grep and other command line tools it is able to extract relevant parts of files into context, not just the whole file itself.
Now I may very well be off here and Cline may do this now, but I’ve found that with this, Claude Code, compared to Cline, is:
- Faster at completing a task
- More Efficient with Context
- Better at coding
The last bullet point may be noise from the 3.7 migration. Cline now supports 3.7 as well, and part of the reason I started to use Claude code in the first place was because 3.7 didn’t work in Cline for a day or two at launch.
However the other two feel undeniable. Claude Code just works. And I love that it’s in a terminal. Because of this, it again feels more like a tool that you can use instead of something that fully takes hold of your development environment (like Cline or Cursor). I appreciate the more a la carte nature it implies, and the immediacy of its action.
I open up a terminal. I get to work.
Working with Claude Code
With Claude Code, a lot of the “lessons” I learned working with Cline were still applicable. Keep files small, know when to cut and run, know what problems the AI would be “good” at, etc.
One difference however was the at-will invocation of Claude 3.7’s new Thinking mode. Prompting Claude Code with “Think Deeply” or anything similar will put Claude Code in a mode somewhat analogous to Cline’s “Think” mode, albeit with the notable difference that it is a discrete mode in terms of Claude and not just a system prompt change like with Cline. The ability to summon this at will is Very Nice. In Cline they felt very much like different modes, but with Claude Code they kind of flow in and out of each other much more smoothly.
The speed and trimness of a terminal-centric development experience started to rewire my brain in terms of how I approach problems. Kind of like how, at 24fps you perceive smooth motion between disparate frames, but don’t at 23. The speed of Claude Code reoriented my own understanding of “coding with AI” — instead of something that was discrete and bounded and task centric, its speed made using it feel more like moving in and out of an ongoing continuous stream of ongoing development.
The best example of this was my evolving relationship to the (presumably!) indefatigable todo list. Typically, when making something, you’ll likely make a list things you want to do. Obviously. You’ll edit and update the list, maybe re-arranging items on the list in terms of priority. Once you have a list of things to do, you start to think about them both in terms of how much you’d like to have those things done as well as which ones are dependencies of others. Additionally, and more importantly, each task takes time (hence it being a “todo” in the first place).
Because these tasks take time, the list itself sort of gathers this weight, or this “burden of implementation/action”. The list itself starts to calcify as a whole thing of “work” that is larger than the sum of its contained items. Lists carry the weight of all the time it takes to do all the items. But not only is a task’s time the time for the specifics of what you wrote, but also all the time spent doing the pre-work to make that thing possible to do at all.
When using something as fast as Claude Code, it makes the time dimension requirement for any task feel like it drops to 0. Near unilaterally for any task [that Claude can do etc etc.].
By the time I finish writing an item on a todo list, assuming it’s well written, I’ve then by proxy already got 50% if not 90-95% of a prompt I could just pass on to Claude Code to just do the work. Even if it does it poorly or it turns out to be a dead end, you can so rapidly test implementation ideas that you are almost better off foregoing the list and working directly with Claude Code.
This is hard to do. Surprisingly so. There is still a place for task lists, but I don’t think it’s also wrong to say that I think we take comfort in the todo list — we hide our own inability to act inside of its own dimensions and priority matrices. Doing the work of writing a nice todo list can give us the sense of having done something without needing to have done something. Or that we can defer to it as work that needs to be done, even if we never do it. We can scapegoat it a bit! It feels good!
Not being able to hide in a task list, requirements, definitions, etc. is scary. It makes you feel a bit exposed. If you use Claude Code (or have used other AI coding tools like Cline), I think you will quickly see in yourself an unwillingness to actually act as fast as the tools allow. I found that I had to constantly push myself to reckon with how fast I could make things with Claude Code. Again, it’s actually kind of scary! It calls your bluffs! It feels safer to just fiddle with a todo list of things you’d like to do someday but surely didn’t have time now.
Claude Code is so fast and so good though that you sort of always have time. If you have a spare 5 minutes, you can make something with Claude Code.
In the morning I’m about to make breakfast, or some coffee. I’ve got my laptop on me, so I send in a prompt for a feature idea I had while coming down the stairs. I put the kettle on, grind some beans, start the coffee. I look out a window. I then come back to my computer a few minutes later to check on the results of the work. The AI finished in a few seconds, obviously, and in that time did probably about an hour or two of dev work.
I think people hear “vibecoding” and “AI-powered coding” and think that means a person is sitting in front of their computer coding, spending the same effective amount of time with their computer, but now with AI. What they don’t think about is how this new era of coding lets you move forward on programming while you’re not actually at the computer.
Claude Code (and Cline) can start a task with no need for onboarding or context building or its own cup of coffee. They are productive immediately. I prompt them and go look out a window while the AI does the work.
Designing Premium Features
When people talk vibecoding, they are very often talking specifically about code. However, correct and even Properly Vibed code doesn’t mean that someone has has produced a commiseratively nice product or application. I think it was Zvi Mowshowitz that described Sonnet 3.7 as “having good default taste,” and I’d agree with that, but any software that is going to be shipped to users is going to need to offer something a bit more than default in order to be compelling enough for someone to pay for, let alone use at all.
For now, AIs are bad at this. They don’t really do “product thinking” by default (unless prompted). I think, once we get some multimodal training data sets for LLMs that associate code and design and UX we’ll be a lot better (maybe by the time you’re reading this we’ll have it!), but for now, it is exceptionally hard for AI to predict good or novel UX patterns.
That means, as a viber(?), you need to be the one to bring these ideas. The best vibers (are we doing this??) will be people that are broadly well studied across in both technical and design disciplines. As an example:
- You should know where responsive break points should be in your application and what your target behavior is for those.
- You should know about common design paradigms and styles
- You need to understand how to work with CSS (AI is exceptionally bad at taking direction to fix it unless it’s overly specific)
- You need to understand architectural and design patterns enough to be able to request them (and validate that they work as intended)
- In a given moment, you likely know what your app needs better than the AI
The current gen of AIs are good, maybe even great. However, they are not “perfect product machines” nor do they approach solving challenges with any sort of “pattern” or “architecture” outside of what the median Github repo may implicitly contain.

These are (obviously) not dealbreakers, but nor would I even describe them as desired. I wouldn’t want an AI that makes a 10/10 product in a one-shot, because there are implicit biases in the design and feature set of that specific thing that likely diverge from what I want (even if I prompt it one way it may turn out I indeed want the opposite!). I like that the current gen of AI AI can produce a solid 7/10 starting point that then either you or the AI can take to 10/10. But closing that gap does require additional knowledge and insight about what the AI is missing that can be easily completely lost if you are purely going off vibes.
For mood, from basically Day 1 I had a strong sense of the product I wanted to build. The version released a year ago had the minimum viable feature set that solved the problem I was targeting: “easy to share, collaborative image galleries”. Creating that required having that idea in the first place with enough context to know that it would be a useful thing to people.
I think there is some hope with models like o3/DeepResearch, etc., that they will be able to do this work for you. To divine from the ether the Perfect Product that you should definitely make. This seems unlikely, if not only because of how LLMs are ostensibly meant to work — either they will give everyone the same result (bad), or have an effectively infinite number of Perfect Ideas (not likely).
This means, at least in the meantime, having strong product sense and goals for what you want to build are key, in part because the AI can, and given time will, build anything. It can turn anything into an everything app, and would likely do that if you continually prompted it for feature improvements.
For mood’s update, I had started to create a list of features that felt like natural extensions of what mood already offered — video uploads, private boards, customization, etc. It’s worth noting that in writing this I rolled back the version of mood locally and asked Claude Code what it thought I should add:
- User authentication system
- Custom tags/categories for media organization
- Themes and appearance customization
- Search functionality for larger galleries
- Social sharing with preview cards
- Slideshow/presentation mode
- Password-protected galleries
- Collaborative editing capabilities
- Basic image editing tools
- Gallery view analytics/stats
These are not bad suggestions! Some are even things I added! But even in prompting for 10 here there is still the matter of choosing what to add and not just adding “everything”. Especially from outside a pure feature list, different features have bigger implications on UI/UX outside of pure functionality, and if your app didn’t already have paradigms for certain interactions, introducing them for one-offs for a random suggested feature would be Bad. Things like Image Editing for example sound great but completely miss what mood is meant for now.
This all comes down to a matter of taste. You have to have good taste or understand what a product needs. Again, I’m wary to state something like this too strongly because I can see ways forward for AIs to get better at a lot of this, but it still feels like it will require human curation to tell an AI when to stop.
Side Vibing
I worked on the premium update for mood for probably for ~1-2 hours a day for a few weeks. This involved a ton of back and forth with the AI in scattered chunks of 10-15 minutes here and there. The project felt “big” (and was — I asked the AI to estimate the time to do the first pass of the migration and premium features with time estimations and it assumed ~1-2 months of full time [human] work).
However, The Vibes Need Not Be So Burdened. When you program something, I find that it’s very easy to forget that you can solve some sort of orthogonal challenge to your current task also with programming. When you’re vibing, it’s easy to forget you can also vibe on the side. And when I’m doing a big main vibe I start to get better at vibing such that I can side vibe even more effectively without getting bogged down in trying to maintain the vibe. Example:
I figured out that, for mood to be more efficient at image loading and layout calculation, it was better to prefetch image dimensions from the server to build out the divs in the gallery layout before fetching the images themselves. I added in code to the server that would now record image dimensions on upload for new images, but existing ones all needed to be back-ported.
Setting up some sort of tool to backport images would require scaffolding some admin tool that, as anyone knows, would itself start to acquire cruft and edge cases and assumptions. I dreaded having to start up another new project. I started thinking about using something like Retool or otherwise.
But then I was like “Wait I can just have the AI make that too”. And less than a minute later:
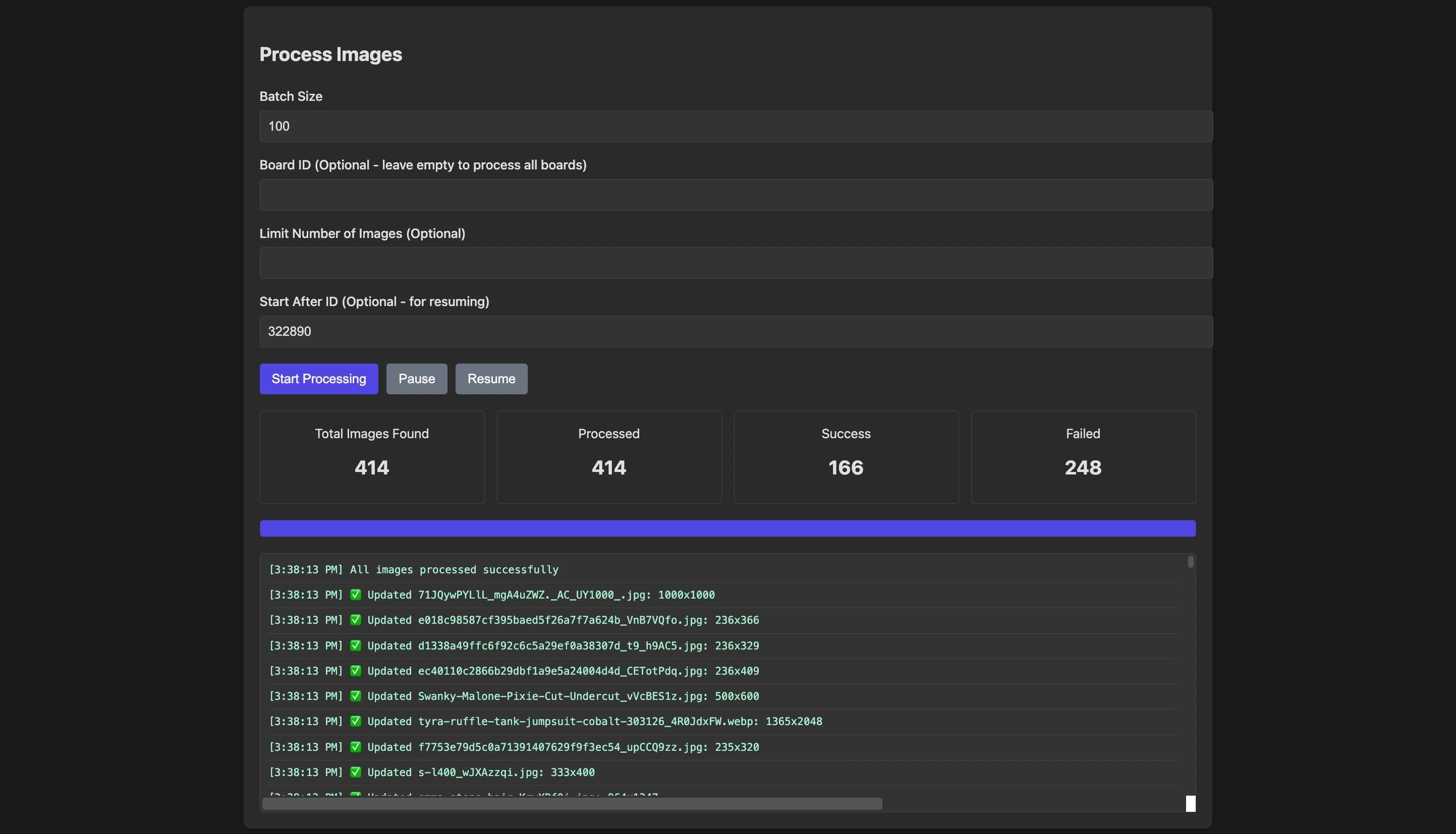
A nice, single-purpose localhost admin tool! I was also able to get the AI to optimize this code and save some web requests and better solve the issue with local code, making everything fast! Creating this from start to finish probably tool less than an hour total. I could delete it and never use it again and feel fine because I know I could immediately make it again.
This sort of one-shot tool is what I imagine when people talk “vibecoding”. Single purpose, one off, quickly created and disposed of. Something you wouldn’t have spent the time to work on before but is something more possible now. It’s great — it works! Even just something like the ability to do this is paradigm-shifting.
The Vibe Shift To Vibecoding Is The New Normal
Working on the little admin tool above after working on mood for (comparatively) so long was really interesting, as it demonstrated how the idea of “vibecoding” can scale. I did it in the reverse order though, working on something big and then something small, but regardless it was easy to see how such a thing is not just some narrowly applicable meme but instead broadly applicable across all manner of software projects.
The speed in which “vibecoding” can produce workable software with GOOD code is truly incredible. Especially considering that the models are the worst they will ever be. I tried hard to avoid any strongly stated deficiencies of the process here, because it seems very clear that whatever hangups or speedbumps I find will continue to improve such that they will be irrelevant by the time you may be reading this.
Even just comparing how the way I code has changed across the past year or two is incredible. From pre-ChatGPT, no Copilot, to where we are now… any step along the way could have sustained a years long “paradigm shift”, but we are getting one now every few months. It is impossible to ignore the gains here and how all this progress is actively reconfiguring how software gets made.
“Vibecoding” is not a trend, but instead some approximation or first baby steps into a new world of software development where humans write far less code but still get product results.
It’s not yet fully superior to coding “like normal,” but it’s impossible deny that it produces work that is about 85% there and about 2-5x as fast (I’d say even 10-20x but I’ve being conservative here). You can try and fail for a few hours with an AI and if it eventually gets it right, it will still likely be more efficient than if someone sat down to do the work in the same period of time.
Moving Forward
mood remains a testbed (and production piece of software!) for trying out novel methods of working with AIs to build software. However with this latest round of working with Claude Code and Cline, what I’ve learned as part of that process has now started to bleed into other projects. The ChatGPT iteration felt like a fun exercise, but wasn’t ergonomic enough to inspire repeated or regular use to build something else. But “vibecoding” and the new “agent” stuff? I’ve definitely started porting over similar tools and methods to other projects that have not, as of yet, used AI tooling outside of completions in VS Code.
Coding in this new way helps me focus more on what I like about programming — problem solving, design, architecture, etc. I feel like I’ve “done my time” already with actually typing out a ton of code, and working with AI like this feels so great to divorce the need to write a ton of code to build something with code.
At the same time, I grant this can be sort of scary, like staring into your own annhilation. Maybe it is! But if there’s an existential threat to this, it’s less about the authorship of code, and more about what the rapid speed and accessibility of these tools means and how you personally (or your employer) relates to the idea of work. Any idea can be whipped up almost immediately. This is obviously incredible, but also becomes coercive. Why not always be making something? Why am I not cooking some agent task in the background while I write this post?

Maybe it’s again that idea I mentioned earlier of me still having some barrier to my understanding of work as being a clearly segmented thing for a time and place instead of something more fluid. Or maybe it’s because I want to focus on only writing this? I’m not sure, and both seem valid.
I know there is a way this can sound dystopian in a similar way to how Slack makes it so you can never really “leave” work (it’s always on your phone in your pocket). But this feels different and more liberating. Things that simply weren’t possible before become possible. The mood.site project, this Svelte update, and then working with Cline and Claude Code, is something I would never have attempted if it wasn’t for AI. I have a full time job and a family, and the time to do it all simply wouldn’t exist.
I think, for everyone, as this only becomes more accessible, there will need to be a boundary renegotiation. Sort of similar to something like Slack adding “work hours” features or national laws about when an employer can or can’t contact you outside of work hours. Maybe all the AIs sleep during the night as well. I’m not sure. Because without this, there is a definite pull now, maybe even an invitation — the AI lies in wait, eager, willing, unflappable, and more than capable. It seems like such a waste to not engage with it.
The Future
To that end, I do plan to continue working on mood with Claude Code (and may try the new OpenAI models in Cline again). I don’t want to save up a big feature backlog again before doing another release, and given the aforementioned tool’s ability to rapidly get back up to speed in a codebase, I suspect I’ll push smaller updates as I improve things. You can read mood’s updates here.
If you got all the way here, thanks for reading! I didn’t expect to write so many words on all of this, but after cutting and editing and adding, I think these piece does do well to represent the state of “vibecoding” and its discontents at this point in 2025. Hope you found this helpful in some way, and I seriously encourage you if you have not already done so to try out Claude Code and Cline. They are truly gamechangers.
And also obviously I’d love for you to use mood, tell your friends, and buy a premium board:
Published on April 18, 2025.